Introduction
In this assignment, you will be writing a program to read in and decode RISC-V assembly files, the ones produced by the single_as program.
This assignment will be autograded using gradescope
This assignment will allow you to exercise a few aspects of the C language including
- command line arguments
- using stdio FILE streams to read files
- dealing with binary files, and endianness
Collaboration
For assignments in CS 2400, you will complete each of them on your own or solo. However, you may discuss high-level ideas with other students, but any viewing, sharing, copying, or dictating of code is forbidden. If you are worried about whether something violates academic integrity, please post on Ed or contact the instructor.
Setup
If you haven’t already, you should follow the Environment setup.
This assignment does not provide you anything, instead you should take the code you built in HW08 and add onto it.
You will have to modify this file and create other files (including a Makefile to finish this assignment).
More details on how to structure your code is in the relevant section below.
There are also separate files that can be used for testing your program. These are mentioned in the testing section below.
Instructions
Your goal in this assignment is to read and disassemble one or more RISC-V object files and produce an ASCII text file continaing what the initial values of program and data memory should like like if those object files were loaded as a program to run. In order to do this, you need to understand the format of the object files produced by our mini assembler. Basically, each object file indicates how various locations in the 32-bit RISC-V memory should be initialized at the start of a program. This includes specifications for both instructions, data, and other information as detailed in the next section.
Object File Format
It is important to note object files are binary files that cannot be read by a human the same way we can open a code file and read that.
To help view the the layout of an object file, the unix utiliy hexdump may be useful. See the hexdump section for more information.
The hexdump section also includes an example of what you could see in an obj file if you looked at it with hexdump.
In this section, we are detailing the file format for RISC-V/penn-sim object files. These binary files are section based, and there are five kinds of sections: code, data, symbol, filename, and linenumber. Each section starts with a fixed size header and may have a body trailing it that would be of some variable length. After one section finishes, another could start and there can be multiple instances of a section in an object file
Note that for the descriptions below, a word is 32-bits (4 bytes), a half is 16-bits (2 bytes), and a character is 8-bits (1-byte).
Each object file should start with the “magic word” containing the value 0xCAFEF00D (32-bits)
Afterwards, the file just contains a sequennce of sections.
Each section is a collection of contiguous bytes and each section starts with a 16-bit indicator so what we know which section we are about to read. Here are the formats of each of the sections:
-
Code:
- 0xC0DE (half)
- <address> (word)
- <n> (word)
- n-word body comprising the instructions.
-
Data:
- 0xDADA (half)
- <address> (word)
- <n> (word)
- n-byte body comprising the initial data values.
-
Symbol:
- 0xC3B7 (half)
- <address> (word)
- <n> (word)
- n-character body comprising the symbol string. (Note: There is no null terminator and each symbol is its own section.)
-
File name:
- 0xF17E (half)
- <n> (word)
- n-character body comprising the filename string. (Note: There is no null terminator and each file name is its own section.)
-
Line number:
- 0x715E (half)
- <addr> (word)
- <line> (word)
- <file-index> (word)
- no body. File-index is the index of the file in the list of file name sections. So if your code comes from two C files, your line number directives should be attached to file numbers 0 or 1.
To get a better understanding of the object file, we highly recommend you look at the hexdump section below.
Although you need to recognize and parse all sections correctly, only the code and data sections actually carry information that is used to populate memory. Since the sections can be interleaved, the symbol, filename, and line number sections only need to be read so that the data and code sections can be read and parsed. You do not need to do anything with the Symbol, File name, and Line number sections once you have read them in.
Endianness
One word of warning about our RISC-V/Penn-sim object files. They are “big-endian”. What does this mean?
Well, the fundamental units of memory and file storage are bytes or char’s (8-bit numbers). Many data types (short’s, int’s) occupy multiple bytes. For instance, you can think of a 2-byte short as byte containing bits 15:8 and another byte containing bits 7:0.
So what is this “big endian” deal? Well, “big endian” just says that multi-byte data-types are represented in files and in memory in mostsignificant-byte to least-significant byte order. So the short value x1234 looks in memory and in a file like x12 followed by x34.
So why does this not go without saying?
Because there are some platforms which are “little-endian” and on these platforms, the value x1234 is laid out in memory and in files as x34 x12.
And, wouldn’t you know it x86 and ARM (the archiectures of your computers and VMs) are “little-endian”.
So when you fread 32 bits from a RISC-V object file on an x86 host, you have to swap the bytes to get the value you expect.
You can look at how sample obj files are formatted with the hexdump tool.
Also note that there are functions to help with converting the byte ordering of data and some are mentioned in the libraries section below.
Output File Format
Your output file should list the non-zero contents of RISC-V memory after all of the object files have been loaded starting from address 0 (though in practice we will start at 0x10000000 since thats the first location we will load our memory into).
Restricting our attention to non-zero entries will make the resulting files significantly more readable.
Your output file will consist of a sequence of lines listing the address as a 4-bytes hex value (So 8 hex “digits”) followed by the contents of that memory location, but as a 1-byte hex value (two hex “digits”). Below is a portion of a sample output describing data memory, code memory is special and will be discussed in a little bit. Here is a sample output for the data portion of memory:
20000020 : FA
20000021 : DE
20000022 : 7E
20000023 : FA
20000024 : AB
20000025 : E0
20000031 : FE
20000032 : B0
20000033 : 56
20000034 : 34
Note that while the address values increase monotonically they need not be sequential since the contents of many memory locations will be zero.
In addition to printing out the contents of memory you are required to pay special attention to memory locations corresponding to code sections.
For our program model, we will say code memory starts at address 0x10000000. Data memory starts at address 0x20000000. To keep things simple in this assignment, you can assume that each section will not exceed 65,536 (2^16) bytes.
For memory locations that are in code memory with non-zero entries you must not only print out the memory contents but also decode the corresponding instruction.
For example, if the memory location at address 0x10000020 contained the hex value 0x00128513 you would print the following line for this entry:
10000020 : 00128513 -> ADDI x5, x10, 1
Similarly, if the memory location at address 0x10008210 contained the hex value 0x00A00A63 you would print the following line for this entry:
10008210 : 00A00A63 -> BEQ x10, x0, 20
For each instruction type you would print out the corresponding mnemonic and format found on the RISC-V instruction sheet. Here are some examples of instruction strings:
ADD x1, x3, x2
ORI x1, x2, 1
BNE x10, x0, -4
The values in immediate fields in the instruction should be printed out as decimal values. Immediate values that are being sign extended should have the appropriate value and sign. Unsigned values will, of course, be positive or zero. If you feel that the instruction cannot be decoded into a legal RISC-V instruction you should print out the string “INVALID INSTRUCTION” after the memory contents for that entry. Please include commas between elements as shown.
In order to decode the instructions, you will want to make use of various C operators for manipulating bit fields.
Operators such as &, |, << and >> can be used to slice and dice 32-bit values as necessary.
The end result of your parsing should be a text file that reflects the assembly code that was originally compiled into the object files.
You can see an example input and output file in the Compiling and Testing section below.
Of course, this version will have explicit offsets in the Branches and Jumps instead of labels.
Code Structure
In this assignment, we are not providing as much starter code as we have provided in past assignments. As a result, you will have to split your program into files yourself and decide what goes in them. In this section we will detail the expected behaviour of your program, and various details that the code you submit must follow.
Overall Program Behaviour
Your program will be invoked from the command line as follows:
$ ./disas output_filename input.o second.o third.o
The first command line argument to your program (after the program name iteslf) is the name of the file you should output your results to. The remaining arguments are the names of RISC-V object files which you should load and decode. You should load the object files in the order they appear in the command line so if a later file overwrites some of the memory locations specified by a previous file the later files values will be the correct result.
Internal Structure
In order to implement your program, you will want to maintain two arrays:
- one of (2^16) 64K ie 64 x 1024=65536 entries with each entry being one byte (e.g. a
uint8_t) corresponding to the entire contents of data memory. - Another array to store the contents of program memory. We assume program memory is at max 2^16 bytes so you could have an array simialr to what we did for data memory or an array of 2^14 entries with each entry being 4-bytes (since an instruction is 4 bytes). Before any object files are loaded you should clear all of these entries to zero.
We provided you decoder.h in the previous assignment and you should have completed decoder.c in that assignment. You will need to build on top of those for this assignment.
The INSTR type has an enumerated field indicating the type of the instruction, 3 fields corresponding to the rs1, rs2 and rd fields of the instruction along with a field to store the immediate field of the instruction.
In order to complete the assignment you will have to finish your insrtuction decoder in decoder.c
In the last assignment you identified the control signals and the instruction type, now you need to go back and in the decoding of the registers and the instruction immediate.
Note that the MUL instruction does not have an immediate value and the SW instruction does not have an Rd field.
If an instruction does not use a particular field in the INSTR struct you do not have to fill it in.
If you feel that the 32 bit input to the function is not a valid RISC-V instruction the type field can be set to ILLEGAL_INSTR.
Note that when you fill in the immediate field of the INSTR struct you are responsible for sign extending or zero extending the field to get the correct result.
This can be done by making appropriate use of bitwise operators like &, and |.
You are strongly encouraged to add additional helper functions to your decoder.c file to implement decode_instr().
You are also allowed (and encouraged) to add fields to the riscv_instr struct but you may not delete or modufy any existing fields.
We plan to test the functions that you write by compiling your decoder.c file against our own test code so please make sure that all of the code you need for these functions is in this file.
As a result, you should not modify the enums or function declaration for decode_instr in decoder.h, but feel free to add anything if you feel it is necessary.
This also means that your main() function can not be in decoder.c.
As part of this assignment we are requiring you to split your code up into multiple files so that you master the process of building programs and writing Makefiles. Your code should be split across:
-
loader.cthat contains the routines you need for opening and loading the object files. Note that since the code is simulating pennsim, we want to store the results of a load into one 65,536 size array (2^16) of bytes for data memory and another large array to hold the insrtuction data.- At a high level, your data array should be setup so that index
iof the array contains the same value as would be stored at addressi + 0x20000000in RISC-V memory. How exactly you do this inloader.cis up to you. You will want to something similar for the instruction array.
- At a high level, your data array should be setup so that index
-
decoder.cthat contains your routines for decoding instructions and printing instructions as described perviously. -
disas.cthat contains yourmain()function and any routines you decide you need to run your program or parse command line arguments. You should have at least two header files,loader.handdecode.hthat contain declarations of the routines in their corresponding.cfiles. You can use more files if you want to but you cannot use fewer. Your final executable should make use of the functions placed inloader.canddecoder.c.
Makefile
You must also write and include a Makefile named Makefile that builds your program from the source components.
Failure to include a working Makefile will result in all tests failing.
The executable that your Makefile produces must be named disas so typing make disas at the command line should make the final executable.
Your Makefile should build intermediate object files for each .c file instead of just building the program all at once and rebuild targets accordingly when their source .h and .c files are updated.
Your Makefile should also contain the phony target clean so that when you type in make clean it removes all object files and the disas exectuable (and nothing else, be sure to not accidentally delete your .c or .h files).
Your Makefile should also compile using the clang-15 compiler and use the -Wall flag at each step to enable all warnings.
If you want to use gdb or valgrind to test your code, you should also compile with the -g3 flag and the -gdwarf-4 flag so that debugging information that is used by these programs are stored in the compilation ouptuts.
The autograder will be testing to make sure that your makefile builds the program as described above.
Compiling and Testing
To compile your code for this assignment, you will have to create your own Makefile (as described above). We suggest looking at the makefile provided with HW08 and shown in lecture slides for a starting point on how you should create your own.
Testing
Gradescope will have public test cases for students to test thier decode_instr and print_instr functions.
Aside from that, we provide some .o and their corresponding output files that you can use to tset your program as a whole.
To utilizes these test cases, you should download the zip in the terminal with:
$ wget https://www.seas.upenn.edu/~cis2400/current/projects/code/hw9_tests.zip
and then unzip the download with:
$ unzip hw9_tests.zip
This wil give you various .o and .txt files (e.g. array.o and array.txt).
The .o files are example inputs into your program and the corresponding .txt file is the sample output.
Once you have run your program and gotten output, you can compare it to the provided sample output. You may find it useful to use the diff command to do this.
diff will compare the two provided files and print out the differences between them. If no differences were detected, nothing is printed out.
Below is an example of running the diff command in the shell.
$ diff file1.txt file2.txt
Compiler Warnings
Sometimes when you compile a C program it will issue warnings. These are the compilers way of telling you that your code is not completely clear, in order to compile your program the compiler had to make some guesses about what you intended which may or may not have been correct. A lot of people figure that if they don’t see an error everything must be fine but that is not a good way to program.
For this assignment you are required to compile all of your code with the –Wall option which turns on all warnings.
Furthermore if we run your makefile and we see any compiler warnings we will be deducting points.
It is your job to make sure that all of the warnings and errors are dealt with before you submit your code.
Coding Environment Differences
Note that there are several subtle and annoying differences between C compilers on different machines.
For this assignment you are expected to use the clang-15 compiler in the environment we provided.
The TAs cannot and will not be responsible for getting code to run on the wide variety of platforms and compilers in use today.
More specifically the TAs will not be responsible for answering questions of the form, “how do I get <fill in the blank> to run on Windows/Mac/etc.”.
Because of the differences between compiler implementations and C libraries on different operating systems getting something to compile and run on one system does not necessarily guarantee that it will work on a different machine.
You should plan on making absolutely sure that your program will compile and run correctly on VM, which is the same environment we will be testing your code on.
The safest way to do that is to develop on that platform.
Valgrind
We will also test your submission on whether there are any memory errors or memory leaks.
We will be using valgrind to do this.
To run it yourself, you should try running: valgrind --leak-check=full ./disas <some arguments here>.
If everything is correct, you should see the following towards the bottom of the output:
==1620== All heap blocks were freed -- no leaks are possible
==1620==
==1620== For counts of detected and suppressed errors, rerun with: -v
==1620== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
If you do not see something similar to the above in your output, valgrind will have printed out details about where the errors and memory leaks occurred.
Other Tools and Hints
Hexdump
hexdump is a unix utility that can be used at the command line to see the contents of a binary file in a more human readable format.
To see the utility of this tool, below we have included what it would look like if we tried to open array.o with a text editor:

You may be able to notice some human readable things in the file like the word “END”, but it is largely unreadable. If we were to instead run the command
$ hexdump -C array.o
we would see the following printed out to the terminal:

From here, the binary file is a lot more readable. Below is an example of someone interpreting the object file “by hand”:
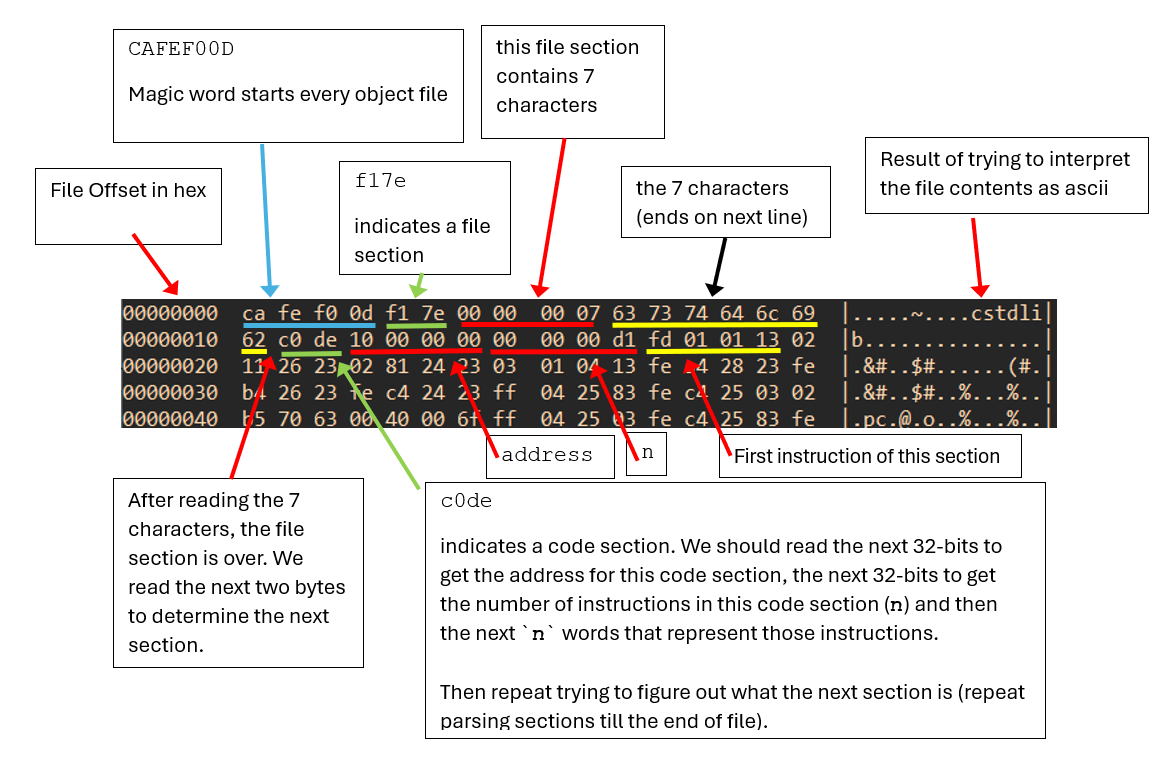
If you would like to store the output of the hexdump operation into a file, you can run:
$ hexdump -C array.o > dump.txt
Where dump.txt is the file where the output will be stored. You can also do this for the other .o files in this assignment
Standard C libraries
In order to program effectively in C you will want to begin to familiarize yourself with the Standard C Libraries. You can find a useful reference to them many places online, though ones that we have liked include:
These utilities are packaged into collections of functions that you can call from your code. In order to avail yourself of these routines you should #include the relevant header files at the beginning of your program like so:
#include <stdio.h>
#include <ctype.h>
Here are some standard C library routines that you may want to look at:
- <stdio.h> fprintf, printf, fopen, fclose, fread, fwrite
- <stdlib.h> malloc, free, exit, EXIT_SUCCESS, EXIT_FAILURE
- <stdint.h> uint16_t, int16_t
- <arpa/inet.h> ntohs, htons, htnol, nthol
The list is only suggestive not comprehensive, and feel free to use other functions that you find in the standard libraries.
One exception to this is that uint32_t must be used since it is in the provided decode.h file.
There are other similar types like int32_t for the signed counterpart and versions for other bit sizes like uint16_t (unsigned 16-bit integer).
You can use all of these as integer types.
The reason we use these types for this assignment is that the size of things is very important since various data we read from the object files are of fixed size and normal C types (e.g. int, short) may have different sizes on different machines.
Submission
Please submit your completed code files to Gradescope