Goals
- Refresher on the basics of C programming (Pointers, output parameters, etc.)
- Refresher on dynamic memory allocation
- Practice with ‘objects’ in C
Collaboration
For assignments in CIT 5950, you will complete each of them on your own or solo. However, you may discuss high-level ideas with other students, but any viewing, sharing, copying, or dictating of code is forbidden. If you are worried about whether something violates academic integrity, please post on Ed or contact the instructor.
Instructions
You will find the starter code in Codiio. Among these files, a few stand out.
Part 1 Files:
-
LinkedList.h: Contains the declarations and extensive comments detailing the functions you will have to implement for part 1 of this assignment. -
LinkedList_priv.h: Contains information about the internal structures used for theLinkedListand its iterator. -
LinkedList.c: Where you will be writing all of your code for the assignment. You will have to implement all of the functions specified inLinkedList.h. -
test_linkedlist.cc: The tests that we will be using to evaluate yourLinkedListimplementation.
Part 2 Files:
-
HashTable.h: Contains the declarations and extensive comments detailing the functions you will have to implement for part 2 of this assignment. -
HashTable_priv.h: Contains information about the internal structures used for theHashTableand its iterator. -
HashTable.c: Where you will be writing all of your code for the assignment. You will have to implement all of the functions specified inHashTable.h. -
test_hashtable.cc: The tests that we will be using to evaluate yourHashTableimplementation..
We recommend reading all of the files for a part before your start that part, especially the .h files listed.
All of the code you will submit for this assignment should be contained in LinkedList.c and HashTable.c. This means that your code should work with the other files as they are when initially supplied.
Note that you can modify the other files if you like, but we will be testing your LinkedList.c and HashTable.c against un-modified versions of the files.
Overview
If you’ve programmed in higher level programming languages like Java, Python, or others, then you probably made use of a large standard library, filled with data structure implementations ready for you to use. In C, we have to make data structures ourselves or use an external library. In this assignment, we will be implementing two fairly common data structures: A Linked-List, a HashTable and iterators for each data structure.
However, C is missing many common features of high-level programming languages, which will make this difficult. In particular, we want to make a generic data structure, with a private implementation, that doesn’t have any memory leaks.
- When we say we want to make a “generic” data structure, we mean we want to make a data structure that can accept any kind of data to stored into it. In other languages, this could be accomplished with templates, such as how you can have a
List\<Integer\>in Java. In C, we are going to use avoid *as our element type, and so users can store pointers to information in our structure. This requires the user to remember how to use the types, and possibly allocate space for the data themselves. - We want to keep the structure private, but we don’t have access modifiers like
publicandprivatein C. Instead, we decide what is part of the public interface vs what is private by what is included in the.hfile. Now we can specify the data type, and some functions that can be used on the type in the public.hfile so that the user doesn’t manipulate the structure directly. - Lastly, unlike high-level languages, C doesn’t have garbage collection. We need to manage memory ourselves using the functions
malloc()andfree().
This assignment is broken into two parts respectively, first you will implement the LinkedList and its corresponding iterator before moving on to the HashTable and its iterator.
Note that despite this assignment being two parts, most students find that the second part with the HashTable and its iterator takes significantly longer to implement.
Part 1: LinkedList
The linked list will be “doubly linked”, which means each node has both a next pointer and a prev pointer to access both the node before it and after it in the list.
At a high level, doubly-linked lists usually look like:
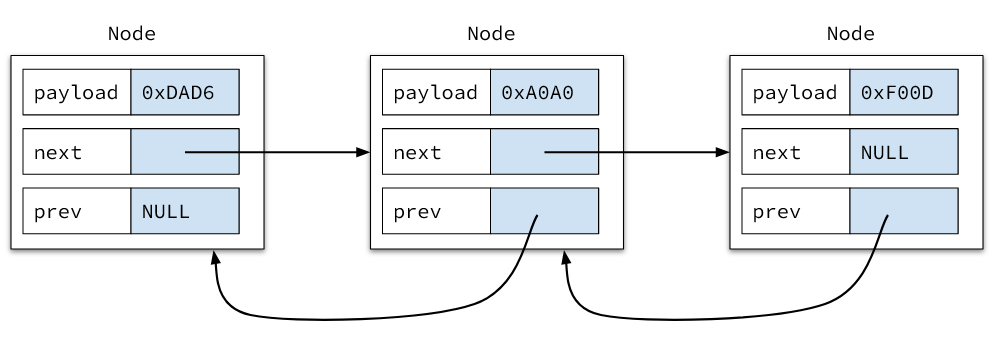
Note in here that each node contains the a pointer to the next node, a pointer to the previous node, and the payload (data) that is stored in that node.
We also use NULL as a value in the prev and next nodes to indicate the absence of a previous or next node.
However, due our goal of wanting to make a full data structure, we don’t want to just give the users of our code LinkedListNodes and tell them to manage the nodes themselves.
As a result, we are going to have a struct called LinkedList that is dedicated to managing the nodes into the form of a List.
LinkedList contains a pointer to the front or “head” of the list, a pointer to the end or “tail” of the list, and the current number of elements in the list.
We can update our drawing to look like this:
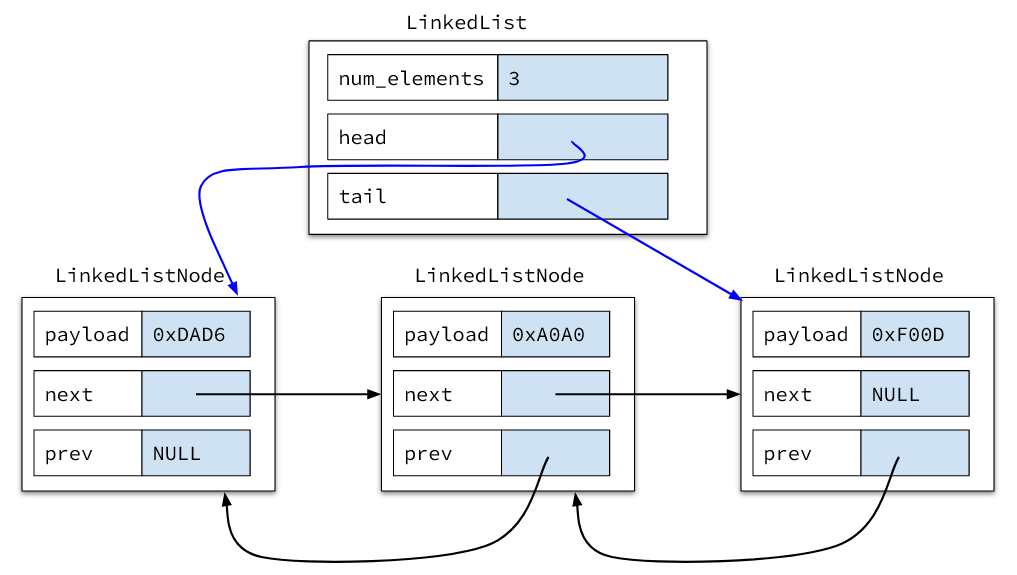
We also want to provide an iterator so that clients can read all the elements in the list, so we will need a third struct called LLIterator.
LLIterator contains a pointer to the current node the iterator is referring to in the list, and a pointer to the LinkedList struct that manages the nodes we are iterating over.
The reason for having a reference to the list itself is because we may have to update things in the LinkedList if we end up removing things with the LLIterator, so the num_elements of the LinkedList and possibly other data may have to change when we remove a node with LLIterator_Remove.
If we add our iterator to the drawing, we get:
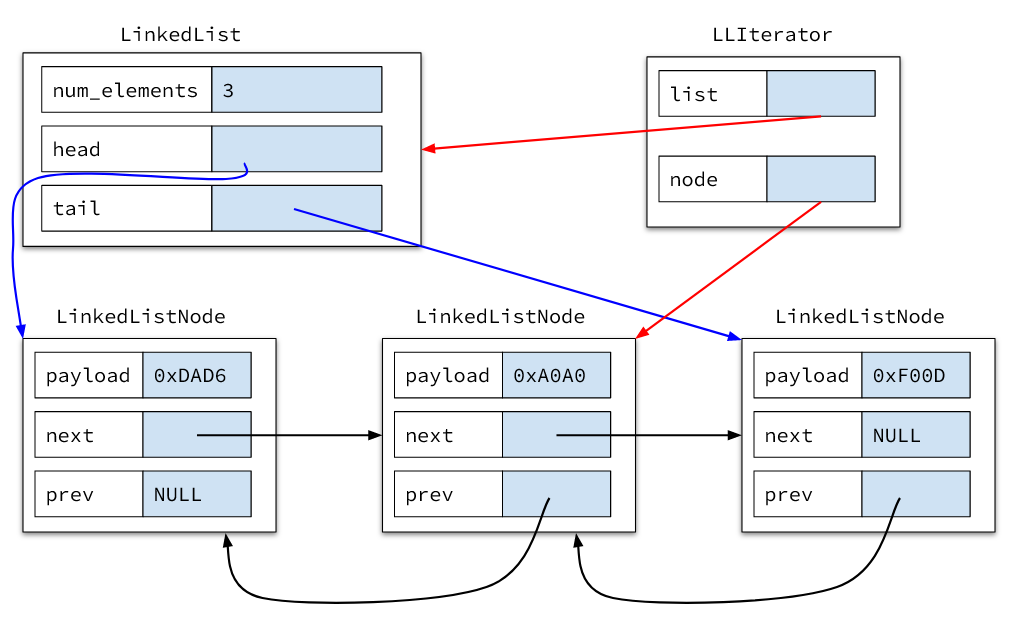
In summary, there are three struct types that we will be using in this part:
-
LinkedList: The structure containing data to maintain the LinkedList, such as the current number of elements, a pointer to the first node, and a pointer to the last node. -
LinkedListNode: The node structure that we will use for our doubly linked list internals. This has apayloadfield, and pointers to thenextandprevelements in the list. -
LLIterator: The structure that represents our iterator. This contains some meta-data necessary for the iterator such as the node it is currently on and a pointer to the overallLinkedList. Note that it is necessary to have a pointer to the overallLinkedListsince the iterator can remove elements which may affect the information stored in theLinkedListstructure.
We will also be using the type LLPayload_t which is a typedef (e.g. alias) for a void *. As mentioned before, this will allow users some flexibility in what the store in the linked list.
Here we have given an overview of the LinkedList structure, your job will be to implement the functions that suppor the implementaiton of our data structure.
Task 1.
Read LinkedList.h, LinkedList_priv.h and implement the incomplete functions in LinkedList.c.
Part 2: HashTable
For part 2, we are implementing a chained hash table. A HashTable allows the user to insert a key/value pair, look up already existing key/value pairs, and remove them. Note that the HashTable is a more complex data structure, and probably something you are not as familiar with. This is OK, this is not a data structures course, please let us know if you have questions on the structure of the HashTable and iterator.
The HashTable structure follows a “chaining” design. This means that our table maintains several LinkedLists which we call “chains” or “buckets”.
When a user inserts a key/value pair, the key will be some hash value of type integer.
The hash table will use a deterministic function to associate that integer with one of the specified buckets.
We can then insert that integer into our HashTable by inserting it into one of our “buckets”.
If we later want to lookup that key/value pair or remove that key/value pair, we can simply look through the bucket associated with that key and avoid looking through the rest of the buckets in our hash table.
One important case to note though, is that if we insert a key/value pair into our HashTable and there is already an entry with the same key/value pair, we will return a copy of the already existing key-value pair to the caller and replace the old key-value pair in the HashTable with the new key/value pair.
To keep the HashTable quick for inserting/lookups/removals we try to keep the buckets short. So as we add more elements to the HashTable, the HashTable will resive to have more buckets and possibly redistribute which keys are associated with wich bucket to keep the buckets short. This resizing is already implemented for you, we just describe it here to give you an idea of what the code is doing.
To get a better understanding of how the HashTable works, we have a diagram below:
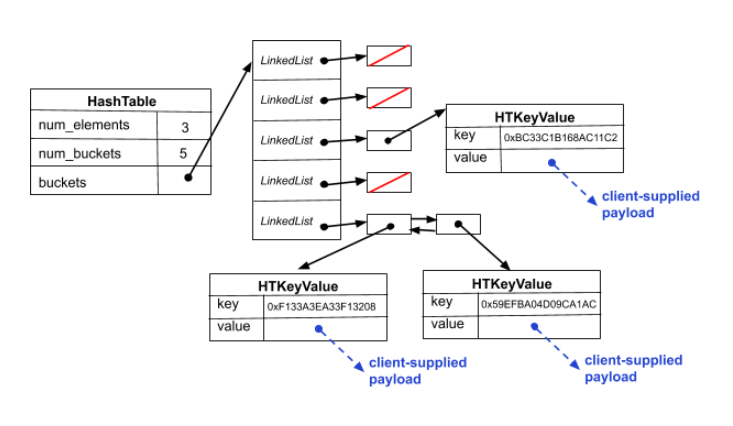
Important to note about this diagram is that we are users of the LinkedList data structure. This means that we must use the functions provded in LinkedList.h to interact with the LinkedList and don’t have direct access to the “private” representation of the list. Note that you are NOT allowed to #include "LinkedList_priv.h" in HashTable.c.
We will also be implementing a HashTable Iterator HTIterator (not pictured) that will iterate through all of the buckets of the HashTable, and each element in each bucket.
More details on the HashTable and HTIterator can be found in HashTable.h and HashTable_priv.h respectively.
We HIGHLY recommend you read these header files before beginning part 2.
Short summary of the structs used in part 2:
-
HTKeyValue_t: Represents a Key-Value pair that we are going to store in our hash table -
HashTable: Contains the data necessary to implement the HashTable: The number of elements in theHashTable, an array ofLinkedList“buckets” where the elements are stored, and the length of the “buckets” array -
HTIterator: The structure that represents our hash table iterator. Contains a pointer to theHashTablethat is currently being iterated over, which bucket in theHashTablewe are iterating over, and the iterator for that bucket.
Task 2.
Read HashTable.h, HashTable_priv.h and implement the incomplete functions in HashTable.c.
Grading & Testing
printf
printf is a C function used for printing output when the program runs.
This is comparable to System.out.println from Java. Since it may have been a while since you programmed in C, here is some basics of using printf that should cover your printing needs for this assignment.
printf can be used on its own to print some string literal represented with double quotes like so: printf("Hello!");.
Note that one of the ways printf is different from System.out.println is that it does NOT print output on a newline for you by default.
If we wanted to make sure that after printing "Hello!" the next thing printed is on a newline, then we have to include the newline character \n in our call to printf like so: printf("Hello!\n");.
Assume we have an integer variable int a; defined somewhere in our code. If you wanted to print out the decimal value of a on a new line, you would write the line of code: printf("%d\n", a);.
We can make our print message have a little more context by modifying the string passed in to printf. An example of this would be: printf("The value of a is %d\n", a);.
If we want to print out the value of a in hexadecimal, we just need to replace the %d with %X. For example printf("%X\n", a);. Note that we cannot print a in binary just using a single call to printf. If you want the exact binary, we recommend you print the value in hexadecimal and convert hexadecimal to binary manually.
Compilation
We have supplied you with a makefile that can be used for compiling your code into an executable. To do this, open the terminal in codio (this can be done by selecting Tools -> Terminal) and then type in make.
You may need to resolve any compiler warnings and compiler errors that show up. Once all compiler errors have been resolved, if you ls in the terminal, you should be able to see an executable called test_suite. You can then run this by typing in ./test_suite to see the evaluation of your code.
Note that your submission will be partially evaluated on the number of compiler warnings. You should eliminate ALL compiler warnings in your code.
Valgrind
We will also test your submission on whether there are any memory errors or memory leaks. We will be using valgrind to do this. To do this, you should try running:
valgrind --leak-check=full ./test_suite
If everything is correct, you should see the following towards the bottom of the output:
==1620== All heap blocks were freed -- no leaks are possible
==1620==
==1620== For counts of detected and suppressed errors, rerun with: -v
==1620== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
If you do not see something similar to the above in your output, valgrind will have printed out details about where the errors and memory leaks occurred.
Gtest
As with mentioned above, you can compile the your implementation by using the make command. This will result in several output files, including an executable called test_suite.
After compiling your solution with make, You can run all of the tests for the homwork by invoking:
$ ./test_suite
You can also run only specific tests by passing command line arguments into test_suite
For example, to only run the LinkedList tests, you can type in:
$ ./test_suite --gtest_filter=Test_LinkedList.*
If you only want to test Push and Pop from LinkedList, you can type in:
$ ./test_suite --gtest_filter=Test_LinkedList.PushPop
You can specify which tests are run for any of the tests in the assingment. You just need to know the names of the tests, and you can do this by running:
$ ./test_suite --gtest_list_tests
These settings can be helpful for debugging specific parts of the assignment, especially since test_suite can be run with these settings through valgrind and gdb!
Submission
Please submit your completed LinkedList.c and HashTable.c to Gradescope
We will be checking for compilation warnings, valgrind errors, making sure the test_suite runs correctly, and that you did not violate any rules established in the specification.