Goals
- Strengthening (and refreshing) skills writing modern style C++ code.
- Developing a strong understanding of how HashTables are implemented
- More practice debugging. The tests are more complex and you will need to put in some effort to figure out where you are encountering issues.
Collaboration
For assignments in CIT 5950, you will complete each of them on your own or solo. However, you may discuss high-level ideas with other students, but any viewing, sharing, copying, or dictating of code is forbidden. If you are worried about whether something violates academic integrity, please post on Ed or contact the instructor.
Contents
Setup
You can downlowd the starter files into your docker container by running the following command:
curl -o ht.zip https://www.seas.upenn.edu/~cit5950/current/projects/code/ht.zip
You can also download the files manually here if you would like: pipe_shell.zip
From here, you need to extract the files by running
unzip ht.zip
Overview
In the zip you will find the following files:
-
hash_table.hpp: Contains the declarations and extensive comments detailing the functions you will have to implement for this assignment. -
hash_table.cpp: Where you will be writing all of your code for the assignment. You will have to implement all of the functions we tell you to implement specified inhash_table.hpp. -
test_hash_table.cpp: The tests that we will be using to evaluate yourhash_tableimplementation..
We recommend reading all of hash_table.hpp and this specifciation before you get started.
All of the code you will submit for this assignment should be contained in hash_table.cpp. This means that your code should work with the other files as they are when initially supplied.
Note that you can modify the other files if you like, but we will be testing your hash_table.cpp against un-modified versions of the files. In particular, modifying test_hash_table.cpp to add print functions may be useful as part of your debugging
Overview
In this assignment, we will be implementing a very common data structure: a hash_table and an iterator for the hash_table.
Task 1.
Read the specification, download the starter files, and read all of hash_table.hpp.
You do not need to include any headers that are not already included for you and you are forbidden from including more.
Part 1a: Core HashTable Functions
For part 1a, we are implementing the core functions of the chained hash table. A hash table allows the user to insert a key/value pair, look up already existing key/value pairs, and erase the key value pair. Note that the hash table is a more complex data structure, and probably something you are not as familiar with. This is OK, this is not a data structures course, please let us know if you have questions on the structure of the hash table and iterator.
We store key value pairs as a std::pair<std::string, std::string> but under the new name kv_pair. If you need to know how to use kv_pair then you should look into the documentation for std::pair.
The hash table structure follows a “chaining” design. This means that our table maintains several linked-lists (e.g. std::list) which we call “chains” or “buckets”.
When a user inserts a key/value pair, the key will be a string.
The hash table will use a deterministic function to associate that string with one of the specified buckets. You can see this in the key_to_bucket_num function.
We can then insert that integer into our hash table by inserting it into the correct bucket.
If we later want to lookup that key/value pair or remove that key/value pair, we can simply look through the bucket associated with that key and avoid looking through the rest of the buckets in our hash table. If your functions for this part loop over every bucket instead of just the associated bucket, you are doing something wrong and may face a deduction.
Our hash table contains the data necessary to implement the hash table: The number of elements in the hash table, a resizable array (std::vector) of linked list (std::list) “buckets” where the elements are stored. Note that we store the kv_pair’s in side of the lists. The size of the array (vector) does not change to hold more lists except in the rehash function.
You should be familiar with a vetcor already, but we have not used the std::list before. To help with this we have a section in the specification below that talks about how to use std::list and it’s iterator.
One important case to note though, is that we insert through the function operator[]. Just like unordered_map in C++, if we use operatpr[] and there is no key/value pair with the associated key in our hash table, then we insert a new pair with the specified key and a default value (the empty string) and return a reference to that empty string. If there is already an entry with the same key/value pair, we will return a reference to the already existing value to the caller.
To get a better understanding of how the hash table works, we have a diagram below:
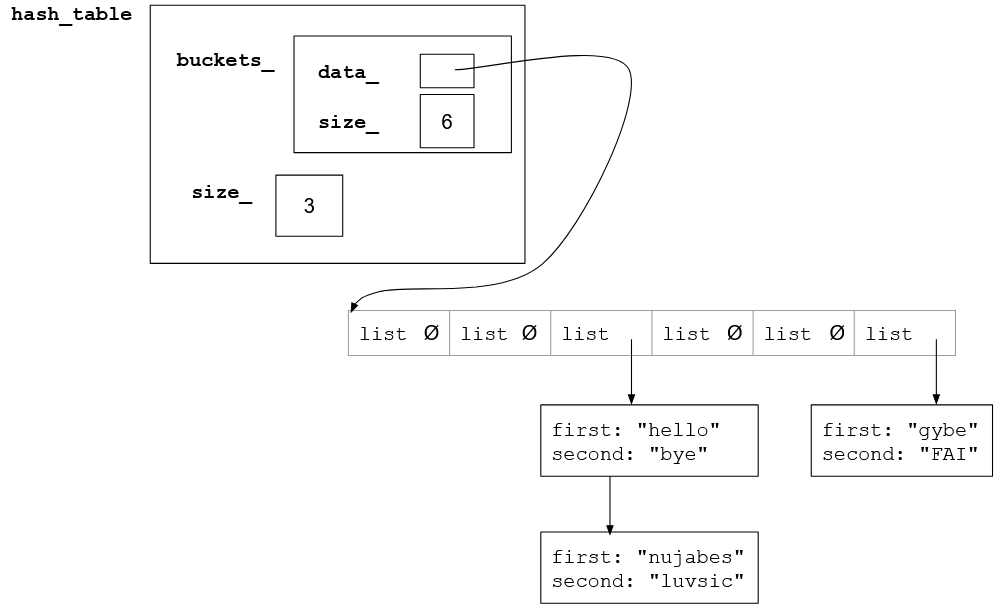
The above diagram is a simplified diagram of what a hashtable looks like in memory. This example hash table has three key-value pairs: {"hello", "bye"}, {"gybe", "FAI"}, and {"nujabes", "luvsic"}. This hash table has 6 buckets in it and the key values are distributed across the buckets based on their key, with two of them in bucket 2 and one of them in bucket 5. Each bucket is a linked list, with many of the linked lists being empty.
Please feel free to ask on Ed if you have questions about the structure of the hash table.
Task 2.
Read the descriptions of the part 1a functions in hash_table.hpp and implement the incomplete functions in hash_table.cpp.
Part 1b: rehashing functions
To keep the HashTable quick for inserting/lookups/removals we try to keep the buckets short. So as we add more elements to the hash table, the hash table will resize to have more buckets and possibly redistribute which keys are associated with wich bucket to keep the buckets short.
This resizing is what you will have to implement for this part of the homework.
You will also need to implement a function that claculates the load factor, which is what we use to determine when we need to resize.
The code that makes your hash table resize when the load factor gets too high is already written for you as part of operator[]. You should not need to modify the code that calls load_factor and rehash from operator[].
Task 2.
Read the descriptions of the part 1b functions in hash_table.hpp and implement the incomplete functions in hash_table.cpp.
Part 2: iterator
We will also be implementing a hash table iterator hash_table::iterator that will iterate through all of the buckets of the hash table, and each element in each bucket.
Our iterator contains a reference to the hash_table that is currently being iterated over, the number of the bucket in the table we are iterating over, and the iterator for that bucket.
More details on the hash_table::iterator can be found in hash_table.hpp.
We highly recommend you read the section on std::list and its iterator in the section below if you have not already.
Task 4.
Read the iterator section of hash_table.hpp and implement the incomplete iterator functions in hash_table.cpp.
Hints
std::list
In this assignment you will be using the std::list as our buckets in the hash table. std::list is the C++ standard library’s implementation of a linked list data structure.
In some langauges like java, the interface for the list is the same whether you are using a LinkedList or an ArrayList. In C++, this is not true. In C++, the interfaces to a std::list and a std::vector are different to encourage different usages of them based on the behaviour you seek.
For example, this code is legal in C++:
vector<int> nums {3, 4, 5}; // construct a vector
cout << nums.at(1) << endl; // access the middle value of the list directly
cout << nums[2] << endl;
whereas if we were to write the same code for a list then it would not compile. This is because a list is a linked list and trying to index into it (also called “random access”) is inefficient. If you wanted to index into it, you should use an alternative data structure (like a vector). If we wanted to access all the values in a list, we should iterate over it using an iterator or a range-for loop. For example:
list<int> nums {3, 4, 5}; // construct a vector
nums.push_back(6); // push_back still supported in linked lists
list::iterator it = nums.begin(); // get an iterator to the vector
while (it != nums.end()) { // while not at the end of the list
cout << *it << endl; // get the value of the current thing we are on and print it
++it; // increment the iterator to the next value
}
// Alternative: using a for loop:
for (auto it2 = nums.begin(); it2 != nums.end(); ++it2) {
cout << *it2 << endl;
++it2;
}
// Alternative: using a range-for loop
for (int& num : nums) {
cout << num << endl;
}
If you understand the above code, that should be enough to get you through this assignment and understanding how to use std::list. However, there is more documentation online if you want:
Grading and Testing
Compilation
You must also modify the provided Makefile to compile the code into a runnable test_suite.
We provide most of the makefile for you, and you will also note that the makefile includes steps for building catch.o and test_suite.o and then using it to compile your test_suite program.
Like past assignments, you will have to build off of what we did in the makefile. This time you will need to make it build test_hash_table.o and hash_table.o from the corresponding cpp and hpp files and then use those to build the test_suite.
This is not as hard as it may sound! It may look scary, but you can do it!
If you need to refresh yourself, then we have a crash course in a previous assignment.
Note that your submission will be partially evaluated on the number of compiler warnings. You should eliminate ALL compiler warnings in your code.
Valgrind
We will also test your submission on whether there are any memory errors or memory leaks. We will be using valgrind to do this. To do this, you should try running:
valgrind --leak-check=full ./test_suite
If everything is correct, you should see the following towards the bottom of the output:
==1620== All heap blocks were freed -- no leaks are possible
==1620==
==1620== For counts of detected and suppressed errors, rerun with: -v
==1620== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
If you do not see something similar to the above in your output, valgrind will have printed out details about where the errors and memory leaks occurred.
Testing
As with mentioned above, you can compile the your implementation by using the make command. This will result in several output files, including an executable called test_suite.
After compiling your solution with make, You can run all of the tests for the homwork by invoking:
$ ./test_suite
You can also run only specific tests by passing command line arguments into test_suite
For example, to only run the tests on the core operations of the hash table (inserting, finding, and removing) you can type in:
$ ./test_suite "InsertFindRemove"
You can specify which tests are run for any of the tests in the assingment. You just need to know the names of the tests, and you can do this by running:
$ ./test_suite --list-tests
These settings can be helpful for debugging specific parts of the assignment, especially since test_suite can be run with these settings through valgrind and gdb!
Clang Format and Clang Tidy
The makefile we provided with this assignment is configured to help make sure your code is properly formatted and follows good (modern) C++ coding conventions.
To do this, we make use of two tools: clang-format and clang-tidy
To make sure your code identation is nice, we have clang format. All you need to do to use this utility, is to run make format, which will run the tool and indent your code propely.
Code that is turned in is expected to follow the specified style, code that is ill-formated must be fixed and re-submitted.
clang-tidy is a more complicated tool. Part of it is checking for style and readability issues but that is not all it does. Examples of readability issues include:
Not using curly braces around if statements and loops:
if (condition) // clang-tidy will complain about missing curly braces
cout << "hello!" << endl;
Declaring variables or parmaters with names that are too short:
void foo(char c) { // clang-tidy will complain about the name `c`
// does something
}
Having functions that are too complex and long. The tool calculates “cognitive complexity” of your code and will complain about anything that is too complex.
This means you should think about how to break your code into helpers, because if you don’t, clang-tidy will complain and you will face a deduction.
More on this specific error can be found here: Cognitive Complexity
clang-tidy is also useful for noticing some memory errors and pointing out bad practices when writing C++ code.
Because of all this, we are enforcing that your code does not produce any clang-tidy errors. You can run clang-tidy on your code by running: make tidy-check.
Whenever you compile your code using make then it should also re-run clang-tidy to check your code for errors.
Note that you will have to fix any compiler errors before clang-tidy will run (and be useful).
Code that has clang-format, clang-tidy or any compiler errors will face a deduction.
If you have any questions about understanding an error, please ask on Ed discussion and we will happily assist you.
Submission
Please submit your completed hash_table.cpp to Gradescope
We will be checking for compilation warnings, valgrind errors, making sure the test_suite runs correctly, and that you did not violate any rules established in the specification.