Prospective Learning: Principled Extrapolation to the Future
Nov 28, 28280
SMODICE: Versatile Offline Imitation Learning via State Occupancy Matching
May 15, 15150
Know Thyself: Transferable Visuomotor Control Through Robot-Awareness
Jan 4, 4040
Conservative and Adaptive Penalty for Model-Based Safe Reinforcement Learning
Jan 1, 1010
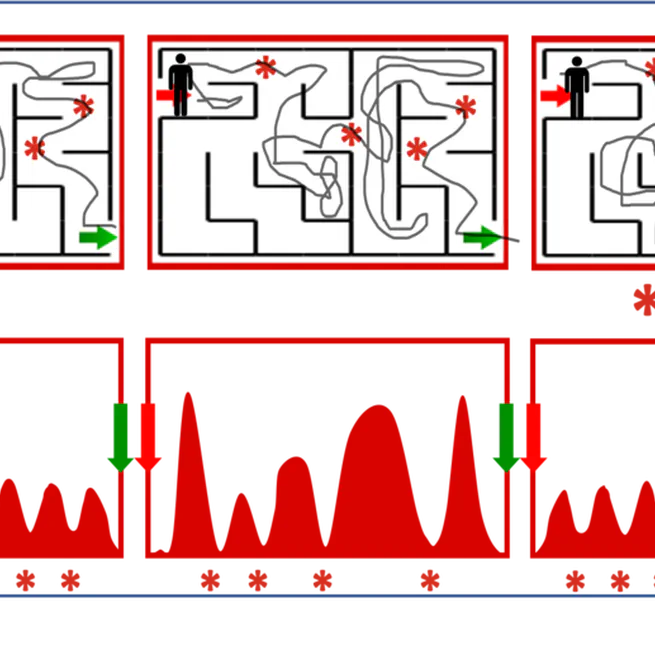
Keyframe-Focused Visual Imitation Learning
Identifying and upsampling important frames from demonstration data can significantly boost imitation learning from histories, and scales easily to complex settings such as autonomous driving from vision.
Oct 8, 8080
Likelihood-Based Diverse Sampling for Trajectory Forecasting
Aug 1, 1010
Conservative Offline Distributional Reinforcement Learning
Aug 1, 1010
How Are Learned Perception-Based Controllers Impacted by the Limits of Robust Control?
We show empirically that the sample complexity and asymptotic performance of learned non-linear controllers in partially observable settings continues to follow theoretical limits based on the difficulty of state estimation
May 7, 7070

SMIRL: Surprise Minimizing RL in Dynamic Environments
We formulate homeostasis as an intrinsic motivation objective and show interesting emergent behavior from minimizing Bayesian surprise with RL across many environments.
Jan 30, 30300
Embracing the Reconstruction Uncertainty in 3D Human Pose Estimation
Jan 1, 1010
Model-Based Inverse Reinforcement Learning from Visual Demonstrations
We learn reward functions in unsupervised object keypoint space, to allow us to follow third-person demonstrations with model-based RL.
Oct 15, 15150
Fighting Copycat Agents in Behavioral Cloning from Multiple Observations.
Oct 15, 15150
Long-Horizon Visual Planning with Goal-Conditioned Hierarchical Predictors
To plan towards long-term goals through visual prediction, we propose a model based on two key ideas: (i) predict in a goal-conditioned way to restrict planning only to useful sequences, and (ii) recursively decompose the goal-conditioned prediction task into an increasingly fine series of subgoals.
Jun 1, 1010
Cautious Adaptation For Reinforcement Learning in Safety-Critical Settings
How to train RL agents safely? We propose to pretrain a model-based agent in a mix of sandbox environments, then plan pessimistically when finetuning in the target environment.
Jun 1, 1010
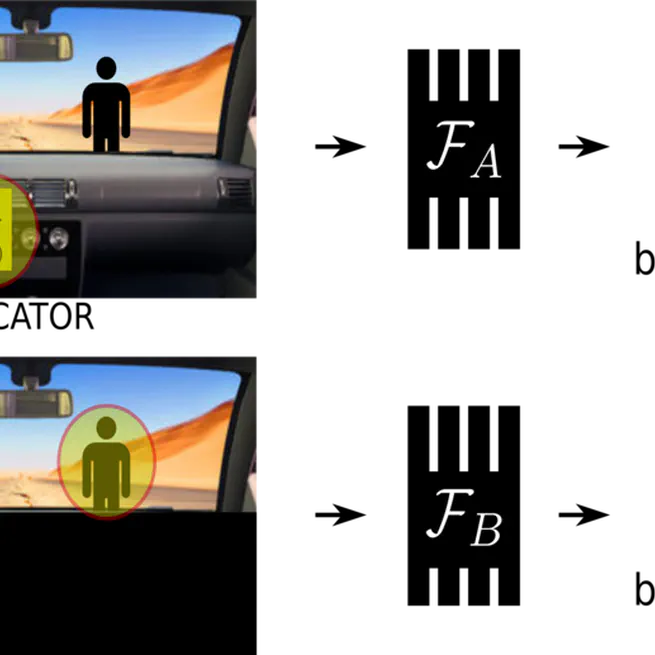
Causal Confusion in Imitation Learning
"Causal confusion", where spurious correlates are mistaken to be causes of expert actions, is commonly prevalent in imitation learning, leading to counterintuitive results where additional information can lead to worse task performance. How might one address this?
Dec 12, 12120
Time-Agnostic Prediction: Predicting Predictable Video Frames
In visual prediction tasks, letting your predictive model choose which times to predict does two things: (i) improves prediction quality, and (ii) leads to semantically coherent "bottleneck state" predictions, which are useful for planning.
Jan 1, 1010

REPLAB: A Reproducible Low-Cost Arm Benchmark Platform for Robotic Learning
We propose a low-cost compact easily replicable hardware stack for manipulation tasks, that can be assembled within a few hours. We also provide implementations of robot learning algorithms for grasping (supervised learning) and reaching (reinforcement learning). Contributions invited!
Jan 1, 1010
Manipulation by Feel: Touch-Based Control with Deep Predictive Models
High-resolution tactile sensing together with visual approaches to prediction and planning with deep neural networks enables high-precision tactile servoing tasks.
Jan 1, 1010
Emergence of Exploratory Look-Around Behaviors Through Active Observation Completion
Jan 1, 1010
ShapeCodes: Self-Supervised Feature Learning by Lifting Views to Viewgrids
Appearance-based image representations in the form of viewgrids provide a useful framework for learning self-supervised image representations by training a network to reconstruct full object shapes, or scenes.
Jan 1, 1010
Learning to Look Around: Intelligently Exploring Unseen Environments for Unknown Tasks
Task-agnostic visual exploration policies may be trained through a proxy "observation completion" task that requires an agent to "paint" unobserved views given a small set of observed views.
Jan 1, 1010
Slow and Steady Feature Analysis: Higher Order Temporal Coherence in Video
Assuming a world that mostly changes smoothly, continuous video streams entail implicit supervision that can be effectively exploited for learning visual representations.
Jan 1, 1010
Pano2Vid: Automatic Cinematography For Watching 360-degree Videos
By exploiting human-uploaded web videos as weak supervision, we may train a system that learns what good videos look like, and tries to automatically direct a virtual camera through precaptured 360-degree videos to try to produce human-like videos.
Jan 1, 1010
Object-Centric Representation Learning from Unlabeled Videos
Unsupervised feature learning from video benefits from paying attention to changes in appearance of objects detected by an objectness measure, rather than only paying attention to the whole scene.
Jan 1, 1010
Look-Ahead Before You Leap: End-to-End Active Recognition By Forecasting the Effect of Motion
Active visual perception with realistic and complex imagery can be formulated as an end-to-end reinforcement learning problem, the solution to which benefits from additionally exploiting the auxiliary task of action-conditioned future prediction.
Jan 1, 1010
Learning Image Representations Tied to Egomotion
An agent's continuous visual observations include information about how the world responds to its actions. This can provide an effective source of self-supervision for learning visual representations.
Jan 1, 1010
Zero-Shot Recognition With Unreliable Attributes
Zero-shot recognition systems often rely on visual attribute classifiers, which may be noisy. However, this noise is systematic, and if modeled correctly and used together with our proposed approach, zero-shot learning outcomes can be significantly improved.
Jan 1, 1010
Decorrelating Semantic Visual Attributes by Resisting the Urge to Share
While learning multiple attributes with possibly noisy correlations in the training set, it helps to employ a multi-task learning approach that tries to learn classifiers that rely on different parts of the input feature space.
Jan 1, 1010
Objective Quality Assessment of Multiply Distorted Images
Image quality assessment datasets have heretofore focused on specific individual distortions rather than a more natural mix of different degrees of various kinds of distortions. We synthesize a dataset to study this latter setting, and compare various existing algorithms.
Jan 1, 1010