VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Jan 1, 1010
Training Robots to Evaluate Robots: Example-Based Interactive Reward Functions for Policy Learning
Sep 13, 13130
How Far I'll Go: Offline Goal-Conditioned Reinforcement Learning via $ f $-Advantage Regression
Jul 1, 1010
SMODICE: Versatile Offline Imitation Learning via State Occupancy Matching
May 15, 15150
Know Thyself: Transferable Visuomotor Control Through Robot-Awareness
Jan 4, 4040
Prospective Learning: Back to the Future
Jan 1, 1010
Conservative and Adaptive Penalty for Model-Based Safe Reinforcement Learning
Jan 1, 1010
Keyframe-Focused Visual Imitation Learning
Identifying and upsampling important frames from demonstration data can significantly boost imitation learning from histories, and scales easily to complex settings such as autonomous driving from vision.
Oct 8, 8080
Conservative Offline Distributional Reinforcement Learning
Aug 1, 1010
How Are Learned Perception-Based Controllers Impacted by the Limits of Robust Control?
We show empirically that the sample complexity and asymptotic performance of learned non-linear controllers in partially observable settings continues to follow theoretical limits based on the difficulty of state estimation
May 7, 7070
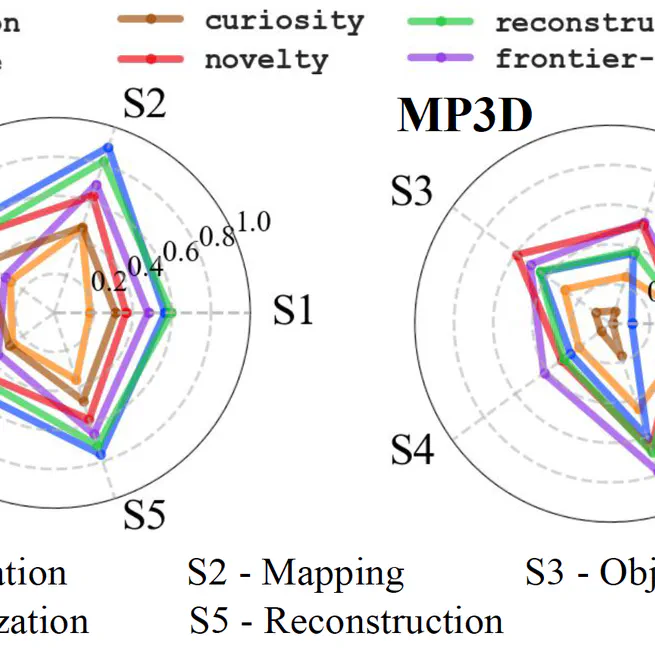
An Exploration of Embodied Visual Exploration
Mar 1, 1010

SMIRL: Surprise Minimizing RL in Dynamic Environments
We formulate homeostasis as an intrinsic motivation objective and show interesting emergent behavior from minimizing Bayesian surprise with RL across many environments.
Jan 30, 30300
Fighting Copycat Agents in Behavioral Cloning from Multiple Observations.
Oct 15, 15150
Long-Horizon Visual Planning with Goal-Conditioned Hierarchical Predictors
To plan towards long-term goals through visual prediction, we propose a model based on two key ideas: (i) predict in a goal-conditioned way to restrict planning only to useful sequences, and (ii) recursively decompose the goal-conditioned prediction task into an increasingly fine series of subgoals.
Jun 1, 1010
Cautious Adaptation For Reinforcement Learning in Safety-Critical Settings
How to train RL agents safely? We propose to pretrain a model-based agent in a mix of sandbox environments, then plan pessimistically when finetuning in the target environment.
Jun 1, 1010
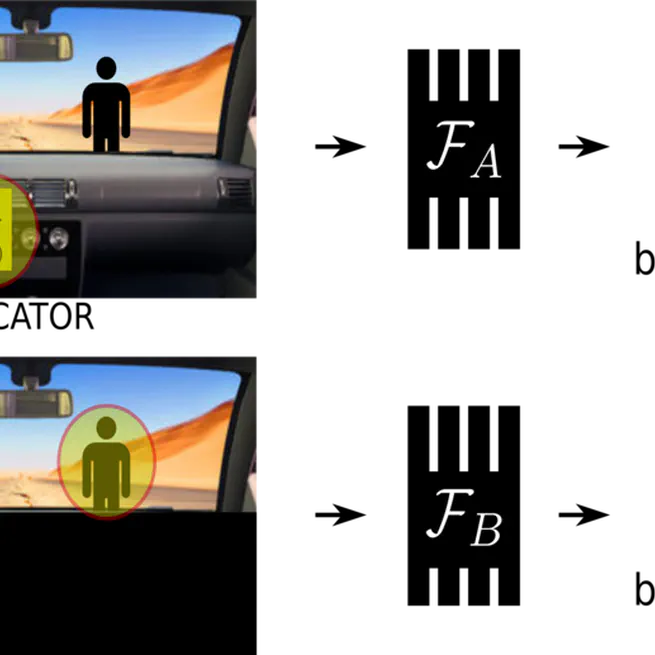
Causal Confusion in Imitation Learning
"Causal confusion", where spurious correlates are mistaken to be causes of expert actions, is commonly prevalent in imitation learning, leading to counterintuitive results where additional information can lead to worse task performance. How might one address this?
Dec 12, 12120

REPLAB: A Reproducible Low-Cost Arm Benchmark Platform for Robotic Learning
We propose a low-cost compact easily replicable hardware stack for manipulation tasks, that can be assembled within a few hours. We also provide implementations of robot learning algorithms for grasping (supervised learning) and reaching (reinforcement learning). Contributions invited!
Jan 1, 1010

REPLAB: A Reproducible Low-Cost Arm Benchmark Platform for Robotic Learning
We propose a low-cost compact easily replicable hardware stack for manipulation tasks, that can be assembled within a few hours. We also provide implementations of robot learning algorithms for grasping (supervised learning) and reaching (reinforcement learning). Contributions invited!
Jan 1, 1010
Emergence of Exploratory Look-Around Behaviors Through Active Observation Completion
Jan 1, 1010
Learning to Look Around: Intelligently Exploring Unseen Environments for Unknown Tasks
Task-agnostic visual exploration policies may be trained through a proxy "observation completion" task that requires an agent to "paint" unobserved views given a small set of observed views.
Jan 1, 1010
End-to-End Policy Learning For Active Visual Categorization
Active visual perception with realistic and complex imagery can be formulated as an end-to-end reinforcement learning problem, the solution to which benefits from additionally exploiting the auxiliary task of action-conditioned future prediction.
Jan 1, 1010
Embodied Learning for Visual Recognition
Jan 1, 1010
Look-Ahead Before You Leap: End-to-End Active Recognition By Forecasting the Effect of Motion
Active visual perception with realistic and complex imagery can be formulated as an end-to-end reinforcement learning problem, the solution to which benefits from additionally exploiting the auxiliary task of action-conditioned future prediction.
Jan 1, 1010