Know Thyself: Transferable Visuomotor Control Through Robot-Awareness
Jan 4, 4040
Conservative Offline Distributional Reinforcement Learning
Aug 1, 1010
Model-Based Inverse Reinforcement Learning from Visual Demonstrations
We learn reward functions in unsupervised object keypoint space, to allow us to follow third-person demonstrations with model-based RL.
Oct 15, 15150
Long-Horizon Visual Planning with Goal-Conditioned Hierarchical Predictors
To plan towards long-term goals through visual prediction, we propose a model based on two key ideas: (i) predict in a goal-conditioned way to restrict planning only to useful sequences, and (ii) recursively decompose the goal-conditioned prediction task into an increasingly fine series of subgoals.
Jun 1, 1010
Cautious Adaptation For Reinforcement Learning in Safety-Critical Settings
How to train RL agents safely? We propose to pretrain a model-based agent in a mix of sandbox environments, then plan pessimistically when finetuning in the target environment.
Jun 1, 1010
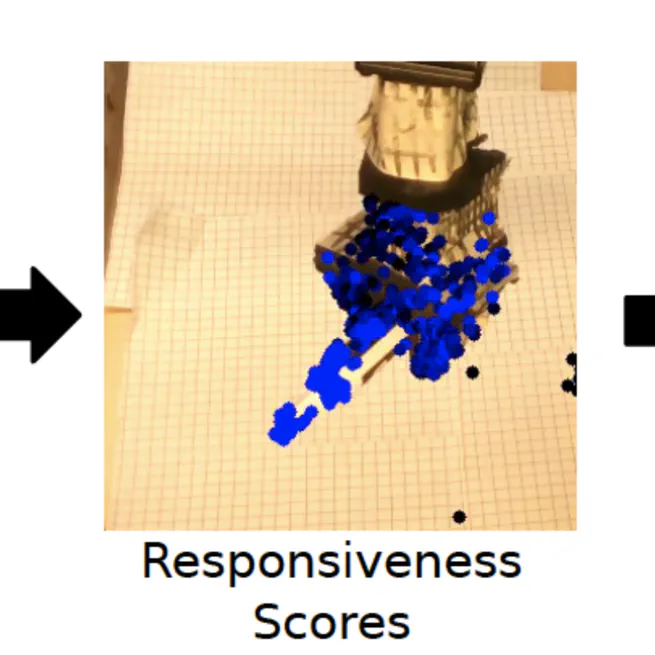
MAVRIC: Morphology-Agnostic Visual Robotic Control
We demonstrate visual control within 20 seconds on a robot with unknown morphology, from a single uncalibrated RGBD camera.
May 17, 17170

DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation
We design and demonstrate a new tactile sensor for in-hand tactile manipulation in a robotic hand.
May 17, 17170
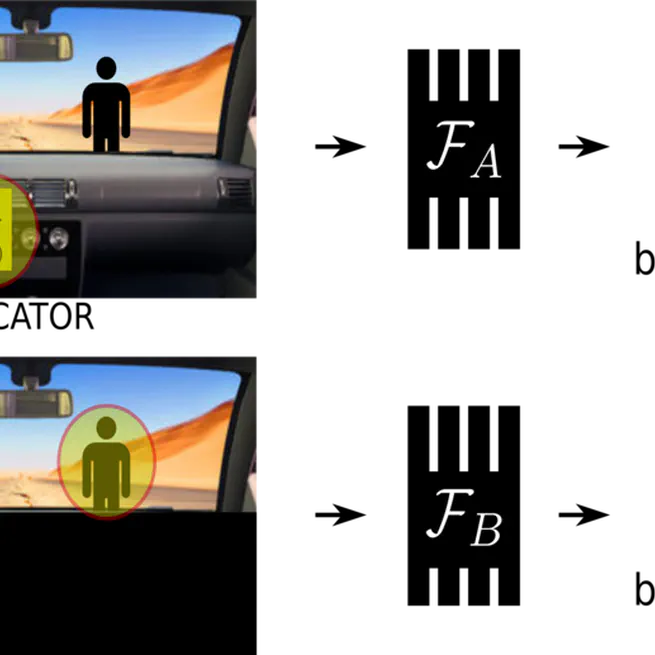
Causal Confusion in Imitation Learning
"Causal confusion", where spurious correlates are mistaken to be causes of expert actions, is commonly prevalent in imitation learning, leading to counterintuitive results where additional information can lead to worse task performance. How might one address this?
Dec 12, 12120
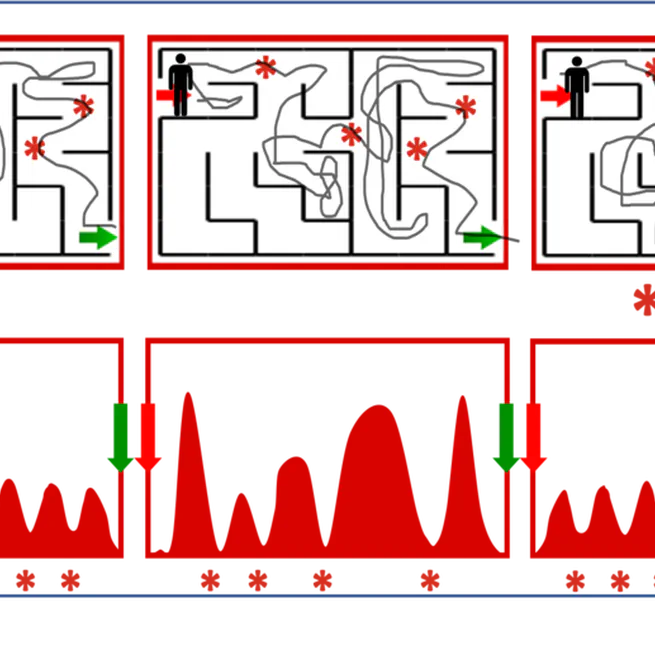
Time-Agnostic Prediction: Predicting Predictable Video Frames
In visual prediction tasks, letting your predictive model choose which times to predict does two things: (i) improves prediction quality, and (ii) leads to semantically coherent "bottleneck state" predictions, which are useful for planning.
Jan 1, 1010

REPLAB: A Reproducible Low-Cost Arm Benchmark Platform for Robotic Learning
We propose a low-cost compact easily replicable hardware stack for manipulation tasks, that can be assembled within a few hours. We also provide implementations of robot learning algorithms for grasping (supervised learning) and reaching (reinforcement learning). Contributions invited!
Jan 1, 1010

REPLAB: A Reproducible Low-Cost Arm Benchmark Platform for Robotic Learning
We propose a low-cost compact easily replicable hardware stack for manipulation tasks, that can be assembled within a few hours. We also provide implementations of robot learning algorithms for grasping (supervised learning) and reaching (reinforcement learning). Contributions invited!
Jan 1, 1010
Manipulation by Feel: Touch-Based Control with Deep Predictive Models
High-resolution tactile sensing together with visual approaches to prediction and planning with deep neural networks enables high-precision tactile servoing tasks.
Jan 1, 1010
More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch
By exploiting high precision tactile sensing with deep learning, robots can effectively iteratively adjust their grasp configurations to boost grasping performance from 65% to 94%.
Jan 1, 1010