
Homework Submission#
Your writeup should follow the writeup guidelines. Your writeup should include your answers to the following questions:
Initial CPU implementation and HLS Kernel
You must have the old SD card image you used for HW3/HW4. Just like we did in HW3/HW4, boot the Ultra96, connect your local machine and the Ultra96, and then copy files in unders the
hw5/hls/to your Ultra96. Find the latency of the matrix multiplier (mmult kernel) usingstopwatchclass inhw5/hls/Testbench.cpp. Use-O3and report it in ms. This is our baseline. (1 line)Now move to Detkin/Ketter Linux machine(or your local machine if you installed Vitis). We will now simulate the matrix multiplier in Vitis HLS.
First, cd to the HW5 directory that you git cloned, and source settings to be able to run vitis_hls.
source sourceMe.sh.If you work locally, source
settings64.shin vitis installation directory.(e.g.:
source /tools/Xilinx/Vitis/2020.2/settings64.sh)You can add line like this above the
export LM_LICENSE_FILE=...line in~/.bashrc.Start Vitis HLS by
vitis_hls &in the terminal. You should now see the IDE.Create a new project and add
hw5/hls/MatrixMultiplication.cppandhw5/hls/MatrixMultiplication.has source files.Specify
mmultas top function.Add
hw5/hls/Testbench.cppas TestBench files.Select the
xczu3eg-sbva484-1-iin the device selection. Use a 150MHz clock, and select Vitis Kernel Flow Target for the Flow Target. Click Finish.Right-click on solution1 and select Solution Settings.
In the General tab, select config_compile command and set pipeline_loops to 0. Vitis HLS automatically does loop pipelining. For the purpose of this homework, we will turn it off, since we are going to do it ourselves.
Run C simulation by right-clicking on the project on the Explorer view, and verify that the test passes in the console. Include the console output in your report.
Note
We set the clock as 150MHz(6.7ns), but you can increase/decrease the clock. The target clock you set in HLS is just a target, but it provides optimization and feedback.
Look at the testbench. How does the testbench verify that the code is correct? (3 lines) (We provide you a testbench here. As you develop your own components for the project, you will need to develop your own testbenches. Our testbenches can serve as an example and template for you.)
Synthesize the matrix multiplier in Vitis HLS. Analyze the Synthesis Report by expanding the solution1 tab in the Explorer view, browsing to syn/report and opening the
.rptfile. What is the expected latency of the hardware accelerator in ms? (1 line)Note
This is “High Level” synthesis. This is the process of translating your C source code to RTL. Logic synthesis that transforms RTL-specified design into a gate-level representation is done on Vivado. Note that the numbers you got from 1-d,e are all estimates!
How many resources of each type (BlockRAM, DSP unit, flip-flop, and LUT) does the implementation consume? (4 lines)
Analyze how the computations are scheduled in time. You can see this information in the Schedule Viewer of the Analysis perspective. How many cycles does a multiplication take? (1 line)
Note
In the Schedule Viewer, you will see Operation\Control Step. Scroll down to the loop you are interested in and click the operation to view the schedule of the operation.
Make a schematic drawing of the hardware implementation consisting of the data path and state machine similar to Figure 2 of the Vitis HLS User Guide. You can ignore the addressing and loop hardware (such as
phi_muxandicmp) in your data path.Explain why the performance of this accelerator is worse than the software implementation. (3 lines)
HLS Kernel Optimization: Loop Unrolling
Go back to the Synthesis perspective, and unroll the loop with label
Main_loop_k2 times using anunrollpragma (See this for an example of unroll pragma). Synthesize the code and look again at the schedule. Does the latency of the entire loop change? Explain the latency discrepancy from the original (non-unrolled).Hint
What characteristic of the original code prevented this optimization? and why is the unrolled loop able to exploit more parallelism?
We could also have unrolled the loop manually. What would the equivalent C code look like?
Inspect the resource usage in the Resource Profile view of the Analysis perspective, as we increase the unroll factor. Of the computational resources (
fmulandfadd) which one(s) are shared by multiple operations? (1 line)Unroll the loop with label
Main_loop_kcompletely, and synthesize the design again. You may notice that the estimated clock period in the Synthesis perspective is shown in red. What does this mean? (3 lines)Change the clock to 100MHz, and synthesize it again. What is the expected latency of the new accelerator in ms? (1 line)
How many resources of each type (BlockRAM, DSP unit, flip-flop, and LUT) does this implementation consume? (4 lines)
You may have noticed that all floating-point additions are scheduled in series. What does this imply about floating-point additions? (2 lines)
We want to multiply two streams of matrices with each other. We can fill the FPGA with copies of one of the accelerators from question 1d(original, 150MHz) or 2e(unrolled, 100MHz). Which accelerator would you choose for the highest throughput?
Hint
We are just asking for a Resource Bound analysis here. How many copies of the each design can you fit in the resources available in Ultra96’s logic? What throughput does each design achieve?
HLS Kernel Optimization: Pipelining
Remove the unroll pragma, and pipeline the
Main_loop_jloop with the minimal initiation interval (II) of 1 using thepipelinepragma. Restore the clock to 150MHz. Synthesize the design again. Report the initiation interval for theMain_loop_jthat the design achieved. (1 line)Draw a schematic for the data path of
Main_loop_jand show how it is connected to the memories. You can find the variables that are mapped onto memories in the Resource Profile view of the Analysis perspective.Assuming a continuous flow of input data, how many data does the pipelined loop need per clock cycle from
Buffer_1? (1 line)Considering what you found in the two previous questions, why does the tool not achieve an initiation interval of 1? (3 lines)
We can partition
Buffer_1andBuffer_2to achieve a better performance. Illustrate the best way to partition each of the arrays with a picture that shows how the elements of these arrays are accessed by one iteration of the pipelined loop.Partition the buffers according to your description in the previous question with the
array_partitionpragma. (See Partitioning Arrays to Improve Pipelining Section of the Vitis HLS User Guide for examples of array partitioning pragma). Also, pipeline theInit_loop_jloop. Synthesize the design and report the expected latency in ms. Provide the modifiedmmultcode in your report.How many resources of each type (BlockRAM, DSP unit, flip-flop, and LUT) does this implementation consume? (4 lines)
Pipeline the
Init_loop_jloop also with an II of 1 and synthesize your design. Before exporting the synthesized design, you can run C/RTL co-simulation to verify that the RTL is functionally identical to the C code.Export your synthesized design by right-clicking on solution1 and then selecting Export RTL. Choose Vitis Kernel (.xo) as the Format. Select output location to be your
ese532_code/hw5directory and select OK. Save your design and quit Vitis HLS. Open a terminal and go to yourese532_code/hw5directory. Run by following the instruction in Building the code section.
Vitis Analyzer
We will now use Vitis Analyzer to analyze the trace of our matrix multiplication on the FPGA.
Run
vitis_analyzer ./mmult.xclbin.run_summaryto open Vitis Analyzer.Find the latency of the matrix multiplication (mmult kernel) by hovering on the kernel call in the application timeline.
Take a screenshot of the Application Timeline. Try to zoom into the relevant section and have everything in one screenshot (start from clEnqueueTask and go till clFinish). Figure out which lines from
Host.cppcorrespond to the sections in the screenshot and annotate the screenshot. Include the annotated screenshot in your report. If you can’t fit everything in one screenshot, take multiple screenshots and annotate. For your reference, following is an example screenshot. Keep the trace in Vitis Analyzer open, we will use the numbers from it in the next section.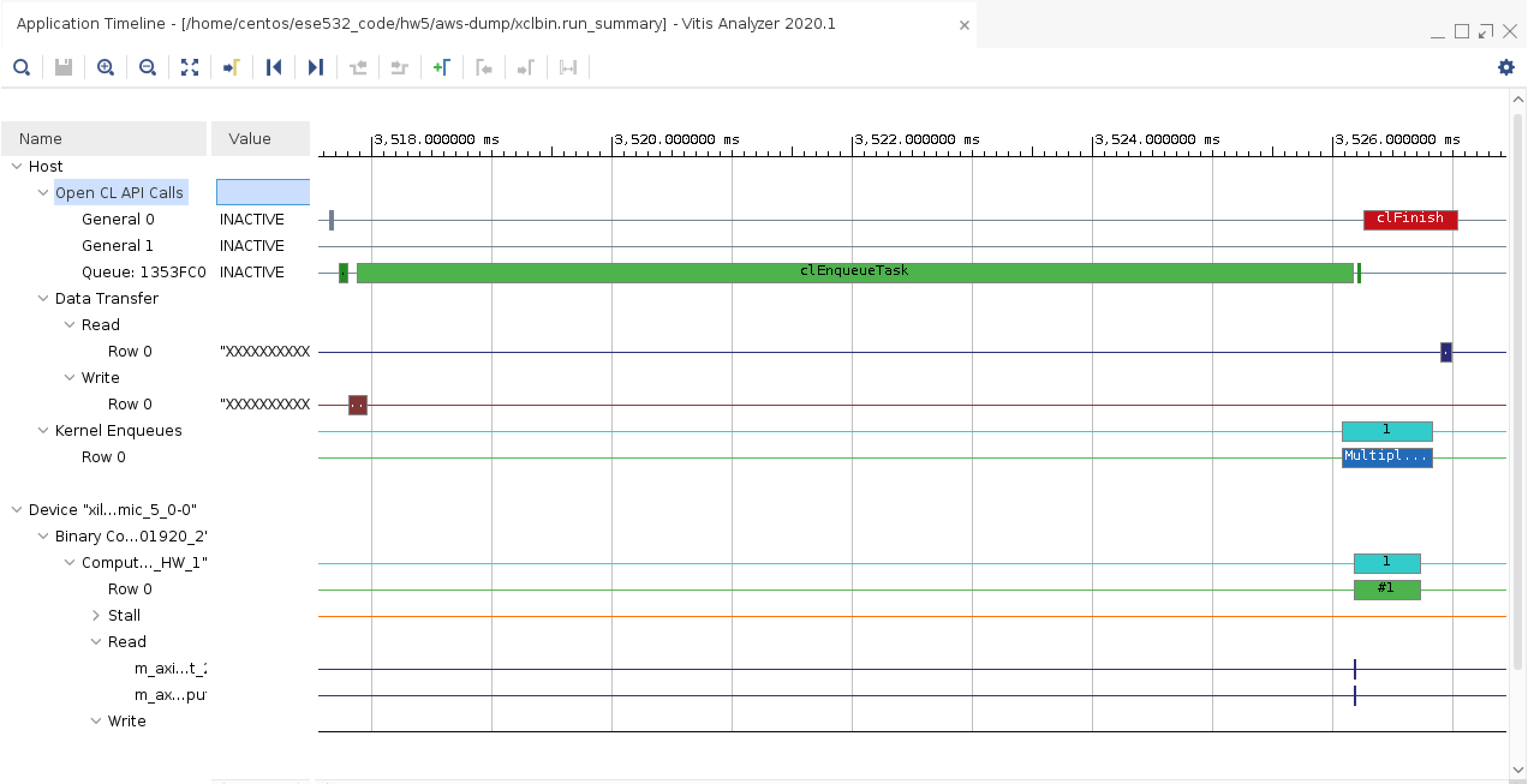
Fig. 19 Example screenshot#
Breakeven and Net Acceleration
We can model an accelerator with setup and transfer time as:
(2)#\[T_{accel} = T_{setup}+T_{transfer}+T_{fpga}\]Let \(T_{seq}\) be the time for an operation (such as the matrix multiply) on the ARM that your found in 1a and \(T_{fpga}\) be the time for the operation on the FPGA that you found in 4b.
Let \(S_{fpga}=\frac{T_{seq}}{T_{fpga}}\) or \(T_{fpga}=\frac{T_{seq}}{S_{fpga}}\).
\(T_{setup}\) is the time to setup the operation and \(T_{transfer}\) is the time to move the data for the operation to the FPGA and back. Include all operations like “create context”, “create program with binary”, etc in \(T_{setup}\).
What is \(S_{fpga}\) for the matrix-multiply operation above?
Find \(T_{setup}\) using the trace in 4c.
Find \(T_{transfer}\) using the trace in 4c.
Using \(S_{fpga}\), \(T_{setup}\), and \(T_{transfer}\) from the above, how large would \(T_{seq}\) need to be to get an actual overall speedup?
Hint
Solve for \(T_{seq}\) in:
\[\frac{T_{seq}}{T_{accel}} > 1\]How does \(T_{seq}\) scale with the matrix dimension \(N\)? (write an equation for \(T_{seq}\) as a function of \(N\)).
How does \(T_{fpga}\) scale with the matrix dimension \(N\)? (write an equation for \(T_{fpga}\) as a function of \(N\)) for your fully unrolled loop strategy from Problem 3 (
Main_loop_jpipelined,Main_loop_kunrolled).How does \(T_{transfer}\) scale with the matrix dimension \(N\)? (write an equation for \(T_{transfer}\) as a function of \(N\)).
Based on 5e, 5f, 5g, for what value of \(N\) would \(T_{accel}\) be equal to the value of \(T_{seq}\)?
Based on the above, for what value of \(N\) would \(T_{accel}=\frac{T_{seq}}{10}\), i.e. what value of \(N\) would show a 10x speedup?
For the value of \(N\) found in 5i, what is the value of \(S_{fpga}\)?
If you perform a large number of accelerator invocations, you only need to perform the setup operations once.
(3)#\[T_{accel} = T_{setup}+k \cdot (T_{transfer}+T_{fpga})\]Assuming the number of invocations, \(k\), is large (say 1 million), how does this change the value of N for 10x speedup ( \(T_{accel}=\frac{T_{seq}}{10}\)) ?
Reflection
Problems 1–3 in this assignment took you through a specific optimization sequence for this task. Describe the optimization sequence in terms of identification and reduction of bottlenecks. (4 lines)
Make an area-time plot for the three designs with a curve for DSPs and BlockRAMs.
Hint
Expected latency (ms) on X-axis, DSPs and BlockRAMs as separate curves on the Y-axis.
Deliverables#
In summary, upload the following in their respective links in canvas:
writeup in pdf.